Small-scale self-supervised learning for images
Motivation
Computer vision is shifting toward foundation models that are largely trained self-supervisedly (i.e. without labeled data) on enormous amounts of data. Such models, for example DINOv2/v3 and V-JEPA 2, achieve state-of-the-art results on most downstream tasks. Exploring new self-supervised learning (SSL) approaches is, however, extremely compute-intensive. Even the smallest common training sets such as ImageNet contain around one million images, while more ambitious ones range from hundreds of millions to billions. This raises a natural question. Is it really necessary to train new SSL methods on that many images, or is a smaller but extremely diverse subset already enough, both to get fast feedback on a new method and, ideally, to reach performance comparable to training on far larger datasets?
Project
This project investigates the role of scale in self-supervised learning (and in related tasks such as model distillation). The central hypothesis is that diversity matters far more than sheer scale, and the goal is to test to what degree this holds for current SSL approaches.
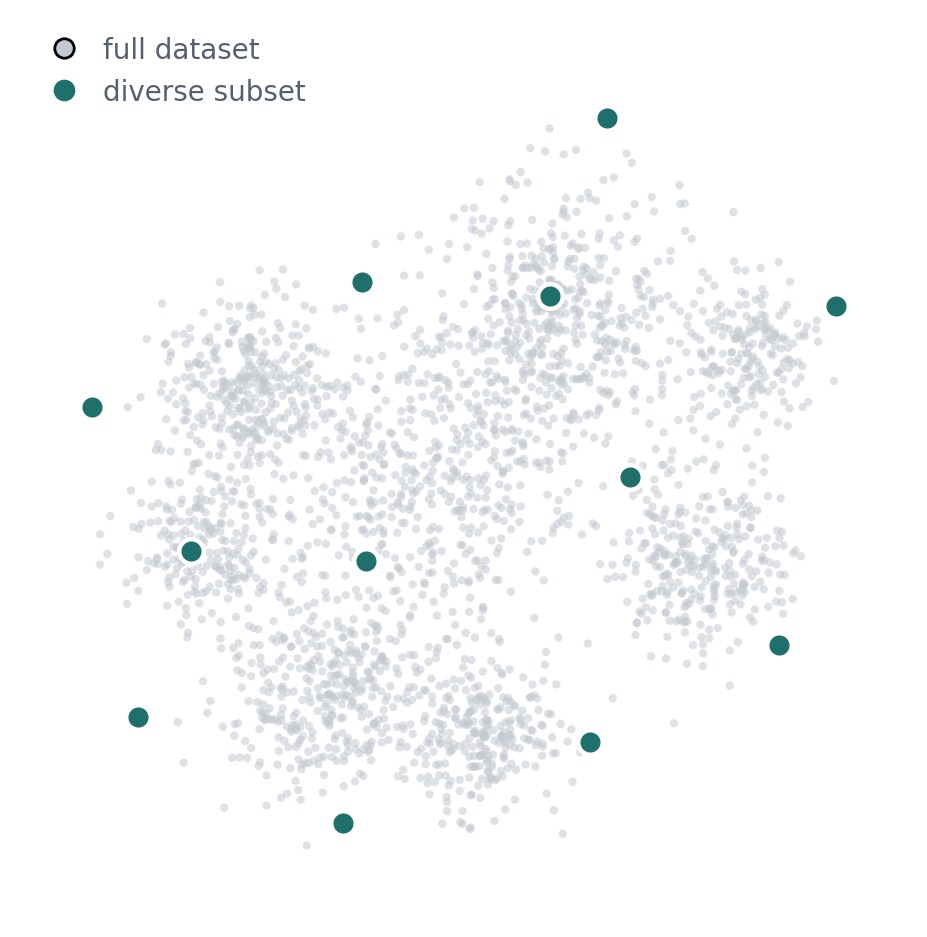
The starting point is concrete. Take a large-scale SSL dataset such as ImageNet-21k or LAION-5B, embed every image with an existing pretrained model, and then sample k maximally diverse images to form a compact subset. We then train several SSL methods (DINOv2, MAE, CLIP, …) on these subsets for varying k and compare their performance.
Depending on the findings, the project can develop in one of several directions.
- If we find a strong correlation between performance on the small subset and on the full dataset, we can use the small subset to iterate on new SSL methods quickly. This would also make SSL research more accessible to labs with limited compute.
- If there is no such correlation, we can analyse why. Are some methods better suited to small data than others? How many samples are needed for reliable estimates? Answering these questions could yield interesting insights into SSL.
- A recent paper, Proteus, showed that model distillation can be done on smaller datasets like ImageNet-1k and that the diversity of the data matters. We could push this further, reducing the amount of data even more while increasing its diversity. This is highly relevant, as it would allow distillation in far less time.
I am also open to other ideas in this space. Depending on your interests or your own ideas, the focus of the thesis can be shifted accordingly.
Thesis
The project begins in a fairly well-defined way and then, based on the early findings and your interests, pivots into one of the directions above. It emphasizes designing sound experiments and carefully analysing the results rather than developing a new model of your own. The aim is to gain genuine insight into SSL and, hopefully, to formulate some practical conclusions about the role of data. I would recommend it as a master’s thesis, since training the models takes a significant amount of time. Overall, the project offers a close look at current trends in computer vision and a lot of hands-on experience with SSL. If you are motivated, I would be glad to work toward a (workshop) paper with you.
Prerequisites
The following skills are required.
- Familiarity with Python (PyTorch, NumPy, and SciPy would be helpful)
- Basic machine learning and deep learning knowledge
Contact
To apply, please email Jan Frederik Meier, stating your interest in the project and detailing your relevant skills. A lab rotation could also be part of this project.
